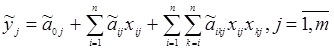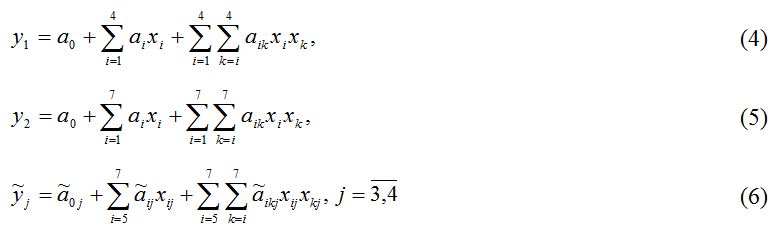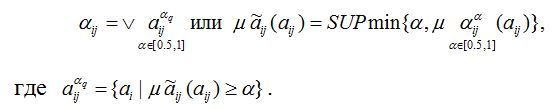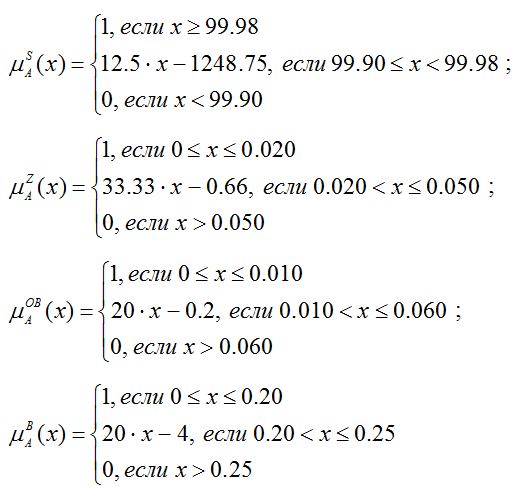Математические модели ХТС производства серы в нечеткой среде для информационных систем и технологий
Mathematical models of ChTS of sulfur production in fuzzy environment for information systems and technologiesУДК 502.65:622.276 23.08.2017 Выходные сведения: Авторы: Authors: Ключевые слова: Keyword: Аннотация: Annotation: Введение Технологические объекты, в которых протекают различные процессы нефтепереработки, в том числе процессы получения серы, и участвует человек в процессе управления ими, относятся к сложным химико-технологическим системам (ХТС). Сложность этих ХТС и задач моделирования, оптимизации и управления ими проявляется в значительном числе и многообразии параметров, определяющих течение процессов, в большом числе внутренних связей между параметрами, в их взаимном влиянии, в неформализуемом действии человека, участвующего в контуре управления. Кроме того, при формализации и решении задач оптимизации режимов и управления ХТС возникает ряд проблем, связанных с множеством критериев, определяющих качество объекта. Многокритериальность исследуемых систем затрудняет разработку математического описания процессов и мероприятий, на основе которых осуществляется процедура оптимизации и управления [1, 2]. На практике часто из-за ненадежности, недостатков или отсутствия необходимых средств измерения, сбора и обработки статистических данных, собранная информация для описания исследуемой системы может оказаться в значительной степени неполной, достаточно неопределенной. Проведение специальных экспериментов для сбора недостающей информации, даже при возможности их проведения, часто оказывается экономически нецелесообразным. Основным источником информации в этих ситуациях является человек (специалист-эксперт, лицо, принимающее решение — ЛПР, технолог), который дает нечеткое описание проблемы, т.е. возникает проблема неопределенности, связанная с нечеткостью исходной информации [3, 4, 5, 6, 7]. Параметры, характеризующие производственные (экономические и экологические) показатели производства, описываются в виде математических моделей – системы уравнений, зависимостей и ограничений. Производственные объекты, ХТС, какими являются объекты глубокой нефтепереработки, разделены определенным образом на подсистемы и элементы, связанные ресурсами и различными потоками (материальные, информационные). При этом каждую подсистему можно описать однотипной системой уравнений обобщенного динамического баланса [8, 9]. Практическое применение такой модели производственных систем возможно при доступности всех составляющих и исходных данных, что часто затруднительно. Кроме того, данная модель довольно громоздкая, неудобная при реализации, т.е. неэффективная при решении задач оптимизации и управления в условиях многокритериальности, дефицита и нечеткости исходной информации. В этой связи в настоящее время актуальными являются методы разработки математических моделей с целью оптимизации и управления ХТС в нечеткой среде. Целью данной работы является разработка методики построения математических моделей многокритериальных ХТС условиях дефицита и нечеткости исходной информации на примере ХТС производства серы.
Результаты исследования и их обсуждение На основе методов теории нечетких множеств и экспертной оценки [3, 4, 5, 6, 7, 10, 11, 12, 13, 14, 15, 16] предлагаем новый эффективный подход к разработке математических моделей технологических агрегатов ХТС, при наличии рассмотренных выше проблем многокритериальности и неопределенности, связанной с нечеткостью исходной информации. В качестве объекта исследования рассмотрим ХТС производства серы, в котором протекают процессы по производства серы из кислого газа. Целевая продукция ХТС производства серы (гранулированная сера) направлена на решение экономико-экологических задач производства, в процессе работы должна отвечать определенным требованиям природоохранных мероприятий, т.е. характеризуются многокритериальностью экономико-экологического характера. Как известно, при моделировании и оптимизации сложных ХТС в условиях неопределенности используется вероятностный подход, основанный на методах теории вероятностей и математической статистики [17, 18, 19]. Однако, на практике не всегда при наличии неопределенностей выполняются аксиомы теории вероятностей (статистическая устойчивость объекта, возможность проведение экспериментов при одинаковых, неизмененных условиях и т.д.), что показывает неправомерность применения этих методов. Более того, в случаях, когда есть основания считать, что процессы или системы ведут себя по вероятностным законам, дефицит информации, невозможность или дороговизна получения достоверных статистических данных толкают на иные пути описания реальных процессов в производственных системах, на разработку нестатистических, например, нечетких методов моделирования объектов. Один из перспективных путей в этом направлении опирается на методы теории нечетких множеств [3, 6, 10]. Таким образом, проблему неопределенности из-за нечеткости исходной информации можно решить созданием математического аппарата для описания и исследования нечетко определенных объектов. К достоинствам методов построения нечетких и лингвистических моделей можно отнести: они позволяют получить эффективные модели объекта в условиях неопределенности, когда традиционные подходы не дают существенных результатов; в моделях, полученных на основе нечетких подходов, учитываются внутренние, содержательные связи основных параметров системы, которые не подлежат формализации, т.е. нечеткие модели позволяют учитывать всю гамму влияния внутренних и внешних параметров процесса. Однако при построении нечетких моделей возникают свои специфические проблемы, например, связанные с проведением экспертного опроса, построением функции принадлежности нечетких параметров, определением структуры условного логического вывода, нечетких регрессионных уравнений и т.д. При построении моделей ХТС, представляющей собой комплекс взаимосвязанных агрегатов различного типа (технологические установки) с различной исходной информацией, приходится использовать комбинированную информацию. В этом случае модели отдельных объектов, т.е. элементов ХТС могут быть построены разными методами, причем должна быть учтена возможность объединения этих моделей в пакет для моделирования работы системы в целом. На практике, при исследовании некоторого объекта, статистические данные для оценки одних параметров могут быть достаточны, а для других параметров – недостаточны или вообще отсутствовать. Параметры таких объектов оцениваются методами, основанными на использовании информации различного характера и объединяющими вышеописанные методы и традиционные подходы к анализу систем. В результате анализа и обобщения возможных подходов моделирования сложных систем при нечеткости исходной информации в данной работе на примере ХТС производства серы предложена методика построения моделей химико-технологических систем в нечеткой среде, включающие следующие основные этапы: 1. Выбираются необходимые для построения модели входные 2. Проводится сбор информации и на основе экспертной процедуры определить терм-множество ( 3. Если xiÎXi, т.е. входные параметры объекта четкие (детерминированы), то определяется структура нечетких уравнений множественной регрессии 4. Строятся функции принадлежности нечетких параметров объекта 5. Если и входные и выходные параметры объекта нечеткие, то строятся лингвистические модели системы и формализуются нечеткие отображения 6. Если выполняются условия пункта 3, то оценить нечеткие значения коэффициентов ( 7. Определяются нечеткие значения параметров объекта и выбираются их числовые значения из нечеткого множества решений. 8. Проверяется условие адекватности модели. Если условие выполняется, то модель рекомендуется для исследования, оптимизации и управления объектом, ХТС, в противном случае определить причину неадекватности и вернуться к предыдущим пунктам для уточнения модели. Дадим пояснения к основным пунктам приведенной методики. В пункте 1 выбираются наиболее информативные переменные, которые характеризуют работы объекта. Для удобства диапазоны изменения нечетко описываемых параметров задаются в виде отрезков, с указанием минимального ( Для построения терм-множества состояний (пункт 2) каждый квант выбранных параметров словесно характеризуется соответствующими нечеткими терминами. Например, если Принятое терм-множество является совокупностью значений лингвистических переменных, описывающих работу исследуемого объекта. Каждый квант, получаемый в i-ом пункте, характеризуется определенным термом. Этому терму соответствует нечеткое множество, которое описывается функцией принадлежности на соответствующем ей уровне градации. Для определения структуры нечетких уравнений множественной регрессии (пункт 3) можно использовать подход нечеткого регрессионного анализа. На этом этапе определяющее значение имеет качественный анализ объекта, в результате которого выявляются основные параметры, влияющие на функционирование, их взаимосвязи и выбирается метод для идентификации структуры модели. Построение функции принадлежности нечетких параметров (пункт 4) является одним из основных этапов при моделировании и оптимизации сложных объектов, ХТС с применением методов теории нечетких множеств. Основным способом восстановления аналитического вида этой функции является графическое построение кривой степени принадлежности того или иного параметра соответствующему нечеткому множеству. На основе полученного графика подбирается такой вид функции, который наилучшим образом аппроксимирует его. После этого идентифицируются параметры выбранной функции. На основе опыта моделирования технологических агрегатов различных ХТС нефтепереработки в нечеткой среде нами предлагается следующая структура функции принадлежности: где Лингвистическая (качественная) модель объекта (пункт 5) строится по результатам обработки экспертной информации с использованием логических правил условного вывода: IF На основе модели, полученной таким образом, формализуются нечеткие отображения Для определения оценки параметров выбранной функции в пункте 3 (параметрическая идентификация) можно воспользоваться критерием минимизации отклонения нечетких значений выходного параметра На этом этапе основным вопросом является выбор способа оценивания неизвестных параметров, обеспечивающего необходимые свойства исследуемого объекта, т.е. элемента ХТС. При этом нечеткие модели имеют вид нечеткого уравнения множественной регрессии [3, 6]: Пункт 7 данной методики построения нечетких моделей заключается в применении композиционного правила вывода: Bj = Ai ° Rij. С помощью этого правила можно осуществлять расчет выходных переменных, например, на основе максиминного произведения: Пусть Прогнозируемые значения выходных переменных (нечеткие значения) определяются в виде соответствующих функций принадлежностей (2). Конкретные числовые значения выходных параметров т.е. выбираются те значения входных параметров, для которых достигается максимум функции принадлежности. Задачей заключительного этапа методики (пункт 8) является проверка соответствия модели объекту. Модель считается адекватной моделируемому объекту, если найденные с ее помощью на компьютере характеристики объекта совпадают с заданной степенью точности, реальными данными, полученными экспериментально на самом объекте. Как правило, в качестве критерия адекватности, являющегося мерой соответствия модели объекту, используется величина рассогласования расчетных (модельных) В случае неадекватности математическая модель определяются источники неадекватности. Причиной, источниками неадекватности модели может быть недооценка значимости какой-нибудь существенной переменной и недоучет ее в модели, неправильная или неполная структура нечетких уравнений, ошибка при параметрической идентификации и т.д. После этого осуществляется возврат к соответствующему пункту алгоритма для доработки модели.
Практическое применение разработанной методики построения математических моделей ХТС в нечеткой среде На основе предложенной выше методики разрабатываем модели реакторов блока производства серы ХТС производства серы функционирующих Атырауского НПЗ. В основу математической модели термореакта F-001 и реактора Клауса R-001 положены статистические данные, экспертная информация обработанные методами теории нечетких множеств, а также уравнения материального и теплового балансов. В результате обработки экспериментально-статистических и экспертных данных, а также применяя идею метода последовательного включения регрессоров, на основе информации различного характера получена следующая структура системы уравнений множественной нечеткой регрессии и условного логического вывода, являющихся моделями исследуемых реакторов: где y1, y2 – соответственно, выход серы с термореактора и реактора Клауса; Как видно, модели описывающие выход продукции с реакторов имеют вид множественной регрессии, соответственно идентифицированы экспериментально-статистическими методами, а модели оценивающие качества серы имеют вид нечетких уравнений множественной регрессии и получены на основе качественной информации от специалистов-экспертов. Идентификация коэффициентов регрессии в моделях (4)‒(6) осуществлены известными методами параметрической идентификации, на основе методов наименьших квадратов с применением пакета программ REGRESS (Кузнецов А.Г., Оразбаев Б.Б.). Результаты параметрической идентификации моделей, определяющих зависимость выхода серы с реакторов, имеют вид (7)‒(8):
Для идентификации неизвестных нечетких коэффициентов Для каждого уровня Полученные значения коэффициентов Таким образом, математические модели, описывающие нечеткую зависимость качественных показателей серы, например, массовая доля серы
Исследование и построение лингвистических моделей определения качества получаемой серы. Для оценки качества получаемой серы на основе логического правила условного вывода и базы знаний построены лингвистические модели, описывающие зависимость качества серы (сортность) от массовой доли серы, массовой доли золы, массовой доли органических веществ и массовой доли воды. Эти модели реализуют лингвистическую зависимость, представляющей собой продукционную базу знаний: -If МS99,98%МZ0,02%МОВ0,01%МВ0,2%, Then QS — «высокое», Else -If МS99,95%МZ0,03%МОВ0,03%МВ0,2%, Then QS — «выше среднего», Else -If МS99,90%МZ0,05%МОВ0,06%МВ0,2%, Then QS — «среднее», Else -If МS99,50%МZ0,20%МОВ0,25%МВ0,2%, Then QS — «ниже среднего», Else -If МS99,20%МZ0,40%МОВ0,50%МВ1,0%, Then QS — «низкое». В вышеприведенной лингвистической модели оценки качества серы приняты следующие обозначения МS — массовая доля серы; МZ – массовая доля золы; МОВ – массовая доля органических веществ; МВ – массовая доля воды; — нечеткое ограничение «не более»; QS – качество серы. На производстве «высокое качество» серы относится к сорту 9998; «выше среднего» – 9995; «среднее» – 9990; «ниже среднее» – 9950; «низкое» – 9920. Как видно из лингвистической модели качество серы, главным образом, зависит от состава серы. Поэтому на практике при нарушении остальных требований (массовая доля золы, органических веществ и воды) качество серы определяется в зависимости от значения первого критерия (требования). На основе этого база знаний дополнена другими условиями и выводами, например: -If МS99,98%МZ0,03%МОВ0,03%МВ0,2%, Then QS — «выше среднего», -If МS99,95%МZ0,04%МОВ0,05%МВ0,5%, Then QS — «среднее», -If МS99,90%МZ0,25%МОВ0,30%МВ0,3%, Then QS — «ниже среднего», -If МS99,50%МZ0,35%МОВ0,50%МВ0,5%, Then QS — «низкое». Таким образом, при нарушении требований к массовой доли золы, органических веществ и воды, сортность качества серы, как правило, определяется одним сортом ниже. Приведенные лингвистические модели в виде продукционной базы знаний позволили формализовать и описать качества и сортность получаемой серы. Функции принадлежности нечетких параметров и показателей качества серы, могут быть построены на основе разработанного в [15] алгоритма построения функции принадлежности, т.е. на основе экспертной информации. Например, функции принадлежности нечетких показателей, описывающие «высокое качество» серы имеет следующие виды [3, 14]: где Заключение В работе предложена методика разработки моделей ХТС на примере установки производства серы в условиях дефицита и нечеткости исходной информации, основанная на применение методов теории систем, методов экспертных оценок и теории нечетких множеств. Дано описание основных пунктов реализации предложенной методики. На основе предлагаемой методики могут быть разработаны: нечеткие модели, имеющие структуру нечетких уравнений множественной регрессии с нечеткими коэффициентами, и лингвистические модели, основанные на применение логических правил условного вывода. Выделены преимущества предлагаемой методики и возможные проблемы при ее реализации. Приведен пример практического применения разработанной методики при построении моделей ХТС производства серы Атырауского НПЗ.
Библиографический список 1.Мушик Э., Мюллер П. Методы принятия технических решений. -М.: Мир, 1990. -208с. References 1.Mushik E., Myuller P. Metody prinyatiya tekhnicheskikh resheniy. -M.: Mir, 1990. -208s. |

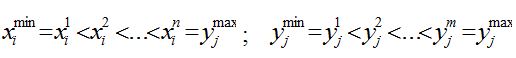 .
.